The Most Important Equation in all of Science
The end of the year is rapidly approaching (just where did 2013 go). I've just spend the week in Canberra at a very interesting meeting, but on the way down I actually thought I was off in to space. Why? Because the new Qantas uniform looks like something from Star Trek.
 Doesn't Qantas know what happens to red shirts?
Doesn't Qantas know what happens to red shirts?
Anyway - why was I in Canberra? I was attending MaxEnt 2013, which, to give it its full name, was the 33rd International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering.
It was a very eclectic meeting, with astronomers, economists, quantum physicists, even people who work on optimizing train networks. So, what was it that brought this range of people together? It was the most important equation in science. Which equation is that, you may ask? It's this one.
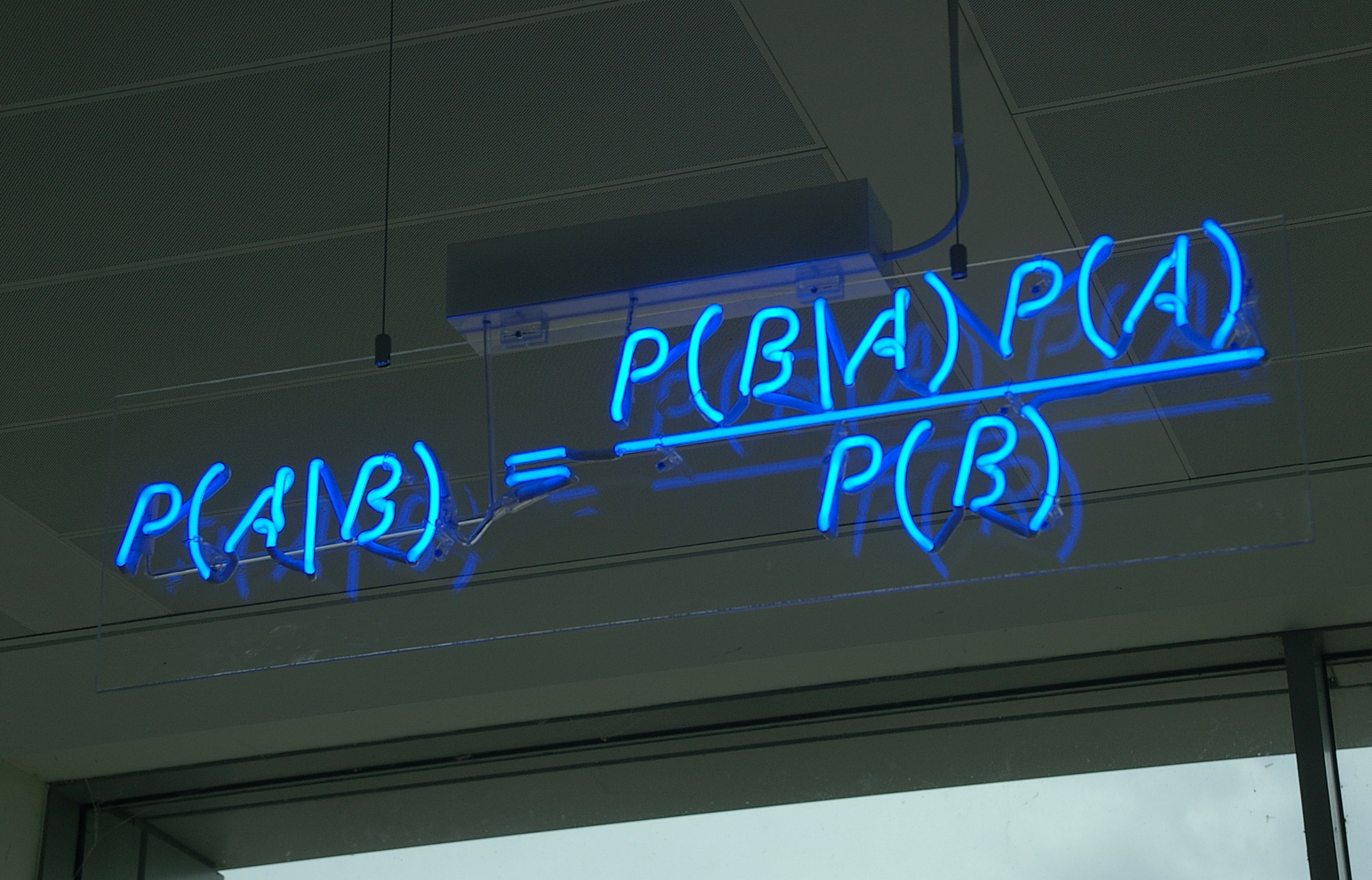 Huh, you may say. I've spoken about this equation multiple times in the past, and what it is, of course, is Bayes Rule.
Huh, you may say. I've spoken about this equation multiple times in the past, and what it is, of course, is Bayes Rule.
Why is it so important? It allows you to update your prior belief, P(A), in light of new new data, B. So, in reality, what it does it connects the two key aspects of science, namely experiment and theory. Now, this is true not only in science done by people in white coats or at telescopes, it is actually how we live our day-to-day lives.
You might be shaking your head saying "I don't like equations, and I definitely haven't solved that one", but luckily it's kind of hardwired in the brain.
As an example, imagine that you were really interested in the height of movie star, Matt Damon (I watched Elysium last night). I know he's an adult male, and to I have an idea that he is likely to be taller than about 1.5m, but is probably less than around 2.5m. This is my prior information. But notice that it is not a single number, it is a range, so my prior contains an uncertainty.
Here, uncertainty has a very well defined meaning. It's the range of heights of Matt Damon that I think are roughly equally likely to be correct. I often wonder if using the word uncertainty confuddles the general public when it comes to talking about science (although it is better than "error" which is what is often used to describe the same thing). Even the most accurate measurements have an uncertainty, but the fact that the range of acceptable answers is narrow is what makes a measurement accurate.
In fact, I don't think that it is incorrect to say that it's not the measurement that gets you the Nobel Prize, but a measurement with a narrow enough uncertainty that allows you to make a decisive statement that does.
I decide to do an internet search, and I find quite quickly that he appears to be 1.78m. Sounds pretty definitive, doesn't it, but a quick look at the internet reveals that this appears to be an over estimate, and he might be closer to closer to 1.72m. So my prior is now updated with this information. In light of this data, it's gone from having a width of a metre to about 10cms. What this means is that the accuracy of my estimate in the height of Matt Damon has improved.
Then, maybe, I am walking down the street with a tape measure, and who should I bump into is Mr Damon himself. With measure in hand, I can get some new, very accurate data, and update my beliefs again. This is how learning processes proceed.
But what does this have to do with science? Well, science proceeds in a very similar fashion. The part that people forget that there is not a group consciousness deciding on what our prior information, P(A), is. This is something inside the mind of each and every researcher.
Let's take a quick example - namely working out the value of Hubble's constant. The usual disclaimer applies here, namely, I am not a historian but I did live through and experience the last stages of the history.
Hubble's constant is a measure of the expansion of the Universe. It comes from Hubble's original work on the recession speed of galaxies, with Hubble discovering that the more distant a galaxy is, the fast it is moving away from us. Here's one of the original measures of this.
 Across the bottom is distance, in parsecs, and up the side is velocity in km/s. So, where does the Hubble constant come in? It's just the relation between the distance and the velocity, such that
Across the bottom is distance, in parsecs, and up the side is velocity in km/s. So, where does the Hubble constant come in? It's just the relation between the distance and the velocity, such that


Anyway - why was I in Canberra? I was attending MaxEnt 2013, which, to give it its full name, was the 33rd International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering.
It was a very eclectic meeting, with astronomers, economists, quantum physicists, even people who work on optimizing train networks. So, what was it that brought this range of people together? It was the most important equation in science. Which equation is that, you may ask? It's this one.
Why is it so important? It allows you to update your prior belief, P(A), in light of new new data, B. So, in reality, what it does it connects the two key aspects of science, namely experiment and theory. Now, this is true not only in science done by people in white coats or at telescopes, it is actually how we live our day-to-day lives.
You might be shaking your head saying "I don't like equations, and I definitely haven't solved that one", but luckily it's kind of hardwired in the brain.
As an example, imagine that you were really interested in the height of movie star, Matt Damon (I watched Elysium last night). I know he's an adult male, and to I have an idea that he is likely to be taller than about 1.5m, but is probably less than around 2.5m. This is my prior information. But notice that it is not a single number, it is a range, so my prior contains an uncertainty.
Here, uncertainty has a very well defined meaning. It's the range of heights of Matt Damon that I think are roughly equally likely to be correct. I often wonder if using the word uncertainty confuddles the general public when it comes to talking about science (although it is better than "error" which is what is often used to describe the same thing). Even the most accurate measurements have an uncertainty, but the fact that the range of acceptable answers is narrow is what makes a measurement accurate.
In fact, I don't think that it is incorrect to say that it's not the measurement that gets you the Nobel Prize, but a measurement with a narrow enough uncertainty that allows you to make a decisive statement that does.
I decide to do an internet search, and I find quite quickly that he appears to be 1.78m. Sounds pretty definitive, doesn't it, but a quick look at the internet reveals that this appears to be an over estimate, and he might be closer to closer to 1.72m. So my prior is now updated with this information. In light of this data, it's gone from having a width of a metre to about 10cms. What this means is that the accuracy of my estimate in the height of Matt Damon has improved.
Then, maybe, I am walking down the street with a tape measure, and who should I bump into is Mr Damon himself. With measure in hand, I can get some new, very accurate data, and update my beliefs again. This is how learning processes proceed.
But what does this have to do with science? Well, science proceeds in a very similar fashion. The part that people forget that there is not a group consciousness deciding on what our prior information, P(A), is. This is something inside the mind of each and every researcher.
Let's take a quick example - namely working out the value of Hubble's constant. The usual disclaimer applies here, namely, I am not a historian but I did live through and experience the last stages of the history.
Hubble's constant is a measure of the expansion of the Universe. It comes from Hubble's original work on the recession speed of galaxies, with Hubble discovering that the more distant a galaxy is, the fast it is moving away from us. Here's one of the original measures of this.
v = Ho D
The awake amongst you will have noted that this is just a linear fit to the data. The even more awake will note that the "constant" is not the normal constant of a linear fit, as this is zero (i.e. the line goes through the origin), but is, in fact, the slope.
So, Hubble's constant is a measure of the rate of expansion of the Universe, and so it is something that we want to know. But we can see there is quite a bit of scatter in the data, and a range straight lines fit the data. In fact, Hubble was way off in his fit as he was suffering from the perennial scientific pain, the systematic error as he didn't know he had the wrong calibration for the cephid variable stars he was looking at.
As I've mentioned before, measuring velocities in astronomy is relatively easy as we can use the Doppler effect. However, distances are difficult; there are whole books on the precarious nature of the cosmological distance ladder.
Anyway, people used different methods to measure the distances, and so got different values of the Hubble constant. Roughly put, some were getting values around 50 km/s/Mpc, whereas others were getting roughly twice this value.
But isn't this rather strange? All of the data were public, so why were there two values floating around? Surely there should be one single value that everyone agreed on?
What was different was the various researchers prior, P(A). What do I mean by this? Well, for those that measured a value around 50 km/s/Mpc, further evidence that found a Hubble's constant about this value reinforced their view, but their priors strongly discounted evidence that it was closer to 100 km/s/Mpc. Whereas those who thought it was about 100 km/s/Mpc discounted the measurements of the researchers who found it to be 50 km/s/Mpc.
This is known as confirmation bias. Notice that it nothing to do with the data, but is in researchers' heads, it is their prior feeling of what they think the answer should be, and their opinion of other researchers and their approaches.
However, as we get more and more data, eventually we should have lots of good, high quality data, so that the data overwhelms the prior information in someone's head. And that's what happened to Hubble's constant. Lots of nice data.
And we find that Hubble's constant is about 72 km/s/Mpc - we could have saved a lot of angst if the 50 km/s/Mpc groups and the 100 km/s/Mpc group split the difference years ago.
It is very important to note that science is not about black-and-white, yes-and-no. It's about gathering evidence and working out which models best describe the data, and using the models to make more predictions. However, it is weighted by your prior expectations, and different people will require differing amounts of information before they change their word view.
This is why ideas often take a while to filter through a community, eventually becoming adopted as the leading explanation.
On a final note, I think to be a good scientist, you have to be careful with your prior ideas and it's very naughty to set a prior on a particular idea to be precisely zero. If you do, then no matter how much evidence you gather, then you will never will be able to accept a new idea; I think we all know people like this, but in science there's a history of people clinging to their ideas, often to the grave, impervious to evidence that contradicts their favoured hypothesis. And again, this has nothing to do with the observations of the Universe, but what is going on in their heads (hey - scientists are people too!).
Anyway, with my non-zero priors, I will update my world-view based upon new observations of the workings of the Universe. And to do this I will use the most important equation in all of science, Bayes rule. And luckily, as part of the MaxEnt meeting, I can now proudly wear Bayes rule where ever I go. Go Bayes :)




Thanks for taking us through that, Geraint. A very clear explanation of the general principle, even if I am still unsure about the darned formula itself!
ReplyDeleteMy question is about the conclusion that Hubble's constant is "about 72 km/s/Mpc". My understanding from Wikipedia (hey - you encourage us to use it) is that that this figure has been refined further, first by WMAP and then by Planck, down to about 67.8 (+/- 0.77)
Is there still uncertainty about these latest refined figures; or is there some other reason you tend to stick with 72?
The whole point of the Bayesian approach is that one additional measurement (here, Planck; WMAP also gives about 72) cannot refine the accepted value in one fell swoop. There are several other independent measurements indicating a somewhat higher value. (Note that we are discussing differences of a few per cent, as opposed to 100 per cent; that's progress!)
DeleteI recently attended the Texas Symposium, where a couple of speakers suggested that there is something wrong with the Planck data in one of the frequency bands. So, my guess is that the Planck value will be revised upward---not because of confirmation bias, but because something is wrong with the current measurement. It also appears that data from this frequency band are not even consistent with other Planck measurements.
Thanks Phillip. Maybe Wikipedia should take the Baysian approach to all the different results which it has listed. It would seem that it has not.
DeleteI understand your point that the Planck data could be revised (as WMAP results were) over time. Thanks!
This comment has been removed by the author.
DeleteOne of the speakers was Spergel. His talk was on 10 December and on 11 December a paper on this topic was posted.
DeleteThe issues with the Planck data mean that some have down-weighted the Planck results. But that's science :)
Deletecephid ---> Cepheid
ReplyDeleteYeah yeah - but the spelling is nothing compared to the myriad of ways I hear the word pronounced.
DeleteJust be happy you didn't study nukuler physics. :-)
DeleteWikipedia even has a redirect for the typo, so your link still works. :-|
DeleteThat dress is much too long to be something out of Star Trek!
ReplyDelete